![[機械学習]タイタニックの生死予測(Dead or Alive)[kaggle]](https://mavericks09.com/mavericks2019/wp-content/uploads/2016/10/ss-1-1.png)
データサイエンティスト、機械学習やディープラーニングなどをやっている人間が集うサイト
kaggle(カグル?)
で実際に機械学習をやってみようと思います。
kaggleでは練習用みたいな問題からコンペもあります。
コンペでは賞金が出るそうです。
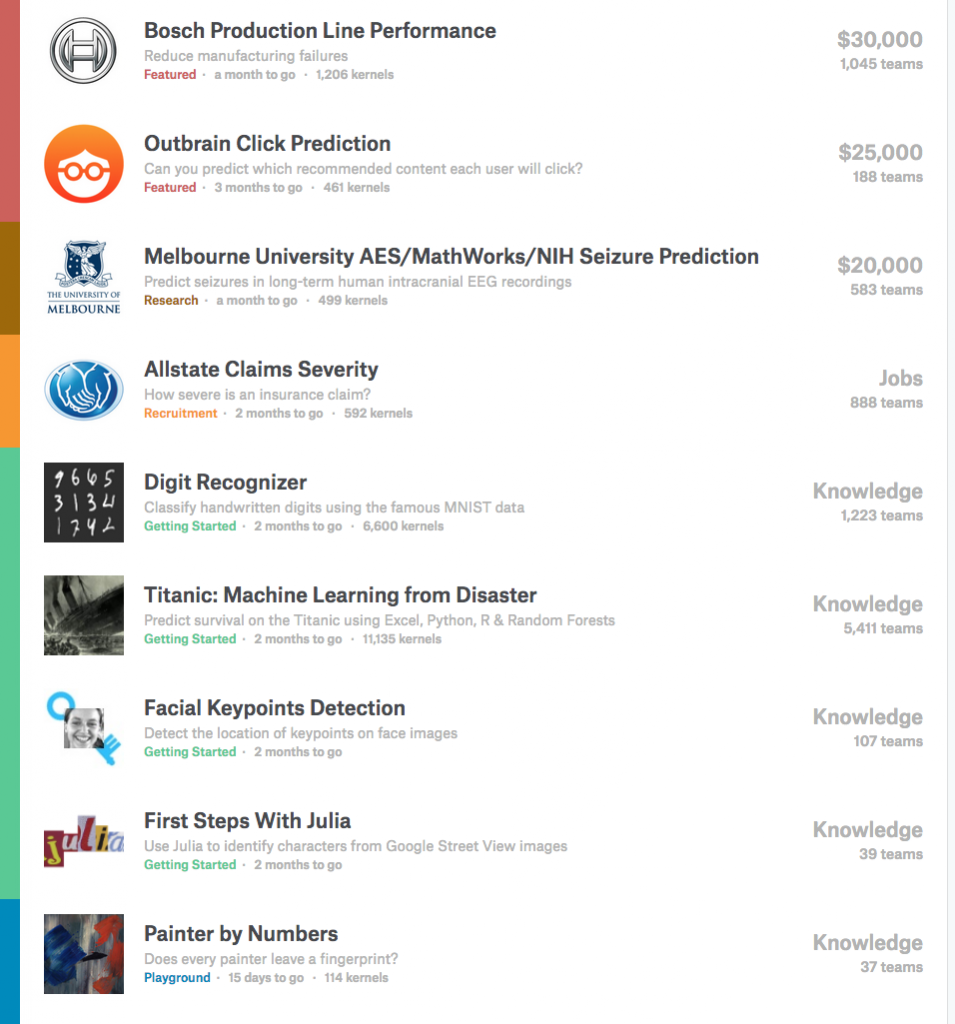
結構な賞金がもらえるものもありますね
今回は有名なタイタニックの生死を予測してみようと思います。
まず訓練データ(CSV)をダウンロード
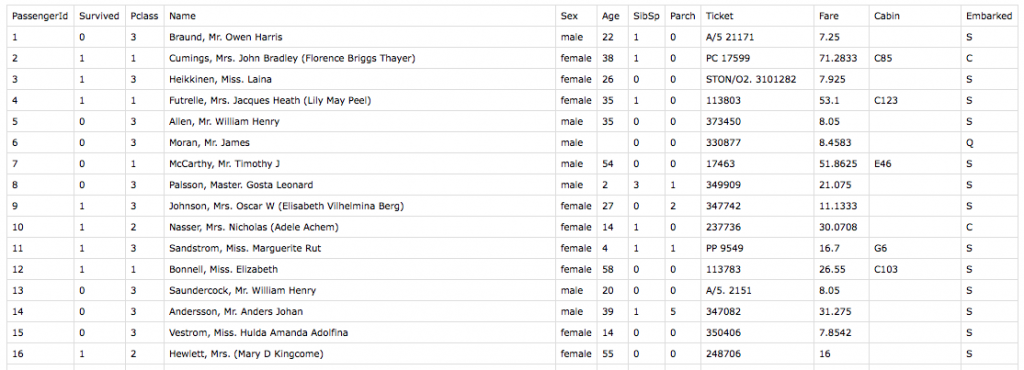
項目は
PassengerId,Survived,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarked
テストデータでSurvived(生死)死=0、生=1を予測します。
単純に考えればDead or Aliveなので50%が通常だと思います。
それをデータから予測します。
まず使えそうな項目を決めます。
ざっと見た感じだとうまく数値化出来そうなのから…
Pclass,Sex,Age,SibSp,Parch,Fare,Embarked
TicketやCabinは部屋の位置などの重要な要素になりそうですが、
Cabinは欠損値(欠測値)が多く、Ticketは規則性がよくわかりません。
Nameから既婚、未婚、家族は誰がいて家族の誰が死んだかを判断出来そうですが、
とりあいずスルーで。
[python]
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn import cross_validation
from sklearn.grid_search import GridSearchCV
import matplotlib.pyplot as plt
%matplotlib inline
[/python]
データの読み込みと性別と乗船した港は数値に変換
このへんはカテゴリー量として扱うかどうかで処理は変わってくると思います。
[python]
df_train= pd.read_csv("data/train.csv").replace("male",0.0).replace("female",1.0).replace("S",0.0).replace("C",1.0).replace("Q",2.0)
df_out= pd.read_csv("data/test.csv").replace("male",0.0).replace("female",1.0).replace("S",0.0).replace("C",1.0).replace("Q",2.0)
[/python]
年齢は欠損値があります。
欠損値の扱いは欠損値のあるデータを除外するのと補完する方法があります。
補完は平均値や中央値で補完したりします。
[python]
age = df_train[[‘Age’]].dropna().values
df = df_train.fillna(np.median(age))
X = df[[‘Age’, ‘Pclass’, ‘Sex’, ‘SibSp’, ‘Parch’,’Fare’, ‘Embarked’]].values
y = df[‘Survived’].values
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.5, random_state=1)
df_out = df_out.fillna(np.median(age))
X_out = df_out[[‘Age’, ‘Pclass’, ‘Sex’, ‘SibSp’, ‘Parch’,’Fare’, ‘Embarked’]].values
[/python]
ランダムフォレストする
[python]
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
[/python]
正解率は大体0.8前後
重要度
[python]
y = clf.feature_importances_
x = np.array([1, 2, 3, 4, 5, 6, 7])
plt.figure(figsize=(16,6))
plt.bar(x*2, y)
plt.xticks(x*2 , [‘Age’, ‘Pclass’, ‘Sex’, ‘SibSp’, ‘Parch’,’Fare’, ‘Embarked’])
plt.show()
clf.feature_importances_
[/python]
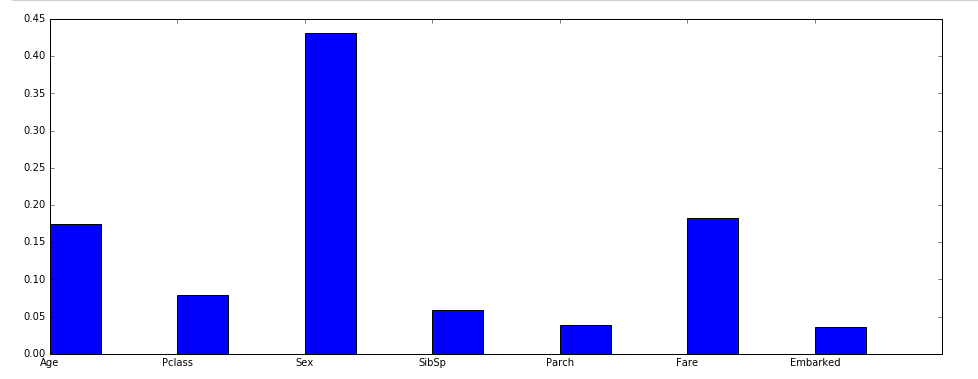
各特徴量の重要度を見る限り、年齢と性別と運賃が大きく影響するようです。
女性子供(年齢、性別)が優先されたのと富裕の差(運賃)が影響しているのではないかと予想出来ます。
今回数字は出しませんが年齢と性別と運賃別の生死グラフを作ると実際どうだったかが分かるかもしれません。
生死の予測データをCSVで吐き出す。
[python]
predicted = clf.predict(X_out)
d = df_out[‘PassengerId’].values
out = pd.DataFrame({ ‘PassengerId’ : d,
‘Survived’ : predicted})
out.to_csv( ‘data/output.csv’,index=False )
[/python]
吐き出したデータをkaggleに送信する。
1日10個までテスト出来るみたいです。
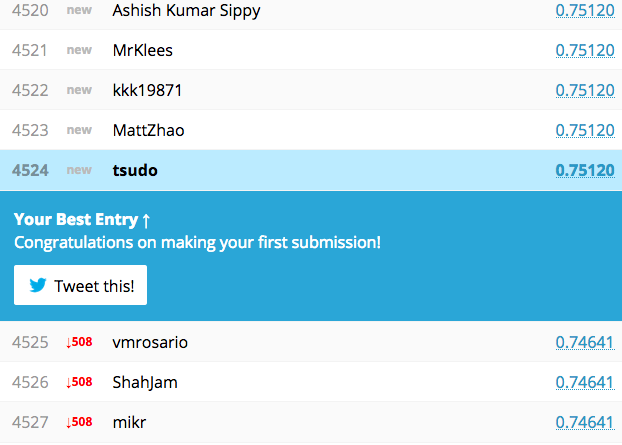
すると結果が返ってきます。
正解率75%…公式のチュートリアルより悪い結果に
色々細々調整した(テストしまくった)結果
んー…大きくは変わりない
根本的なデータの加工が必要そう…
どんな加工やアルゴリズムを使ったか公開している人もいるので色々勉強になりそうです。
データをすごい加工していたり、色んなアルゴリズムを使ってアンサンブルしてたりするみたいです。
正解率100%の人もいるけどこれは・・・?
正直マーケティングとかビックデータの活用とかまったくこれっぽっちも興味ないけど、
こういうゲーム感覚でスコアを上げる工夫を考えるのは結構楽しいかもしれないと思ったんでした。
全然スコアあがんねーけど。
