![[機械学習]決定木とランダムフォレスト](https://mavericks09.com/mavericks2019/wp-content/uploads/2016/10/sa-3-1.png)
色々ある機械学習の中でも大体優秀なランダムフォレスト
スケーリングする必要がない、仕組みが分かりやすい、特徴量いっぱいでも大丈夫っぽい、精度良いのが多い。
ランダムな森?乱れる森?でたらめな森?ん?
ランダムフォレストは決定木の集団(アンサンブル)学習の一つで
決定木は条件からどんどん分岐していって分類していくものらしいです
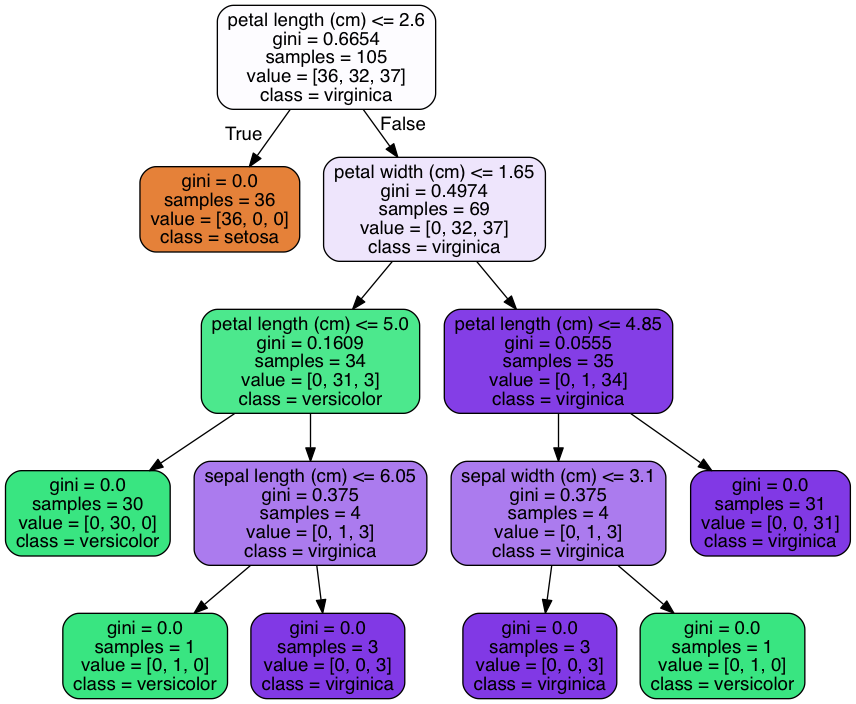
上の例ではIris(アヤメ)をセトナ(setosa)、バーシクル(versicolor)、 バージニカ(virginica)
の3種類を花びらのサイズやがく片の長さなどから分類するもの
訓練データとテストデータ半分ずつ分けて大体正解率92%
ちょっとどうなってんのかわかんないので
今度はダミーデータを使って分類をグラフで見てみる!
特徴量が多いとプロットできないので2次元で!
[python]
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn
from sklearn.datasets import make_blobs
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
[/python]
[python]
X, y = make_blobs(n_samples=4000, centers=8, random_state=10, cluster_std=1.6)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5)
[/python]
ダミーのデータの作成、訓練データとテストデータを分ける。
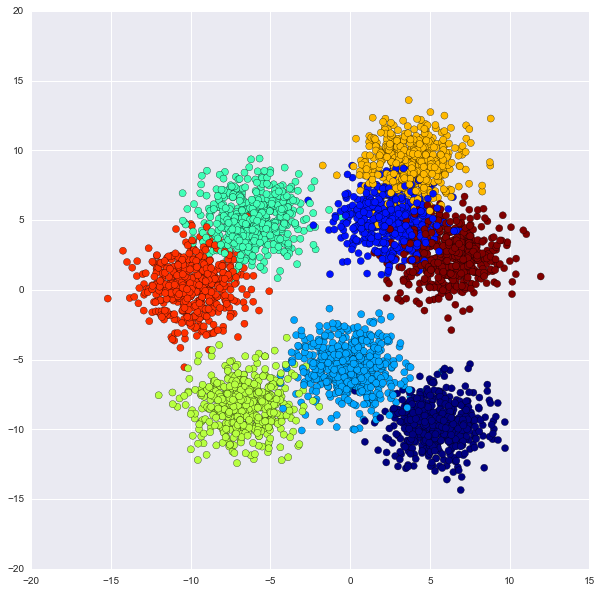
全データプロット
□決定木
[python]
clf = DecisionTreeClassifier(max_depth=3, random_state = 0)
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
[/python]
max_depthは決定木の最大深さ
max_depth=3の場合
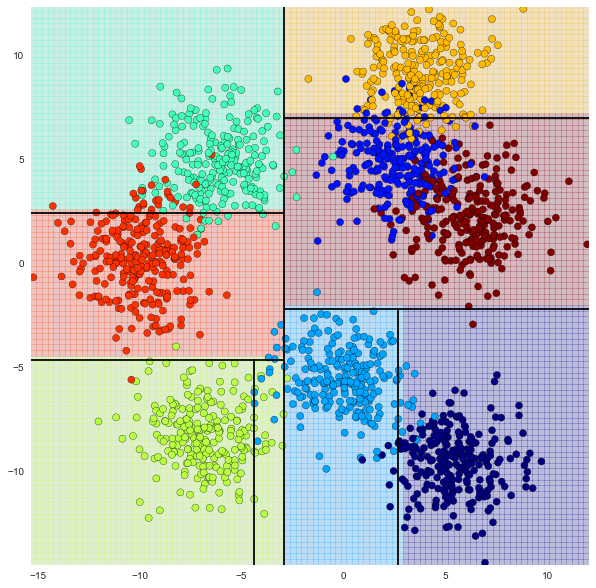
薄い色で埋め尽くされている部分が各点(色)の分類した場所
score 0.82750000000000001
結構まじってんな
max_depth=6の場合
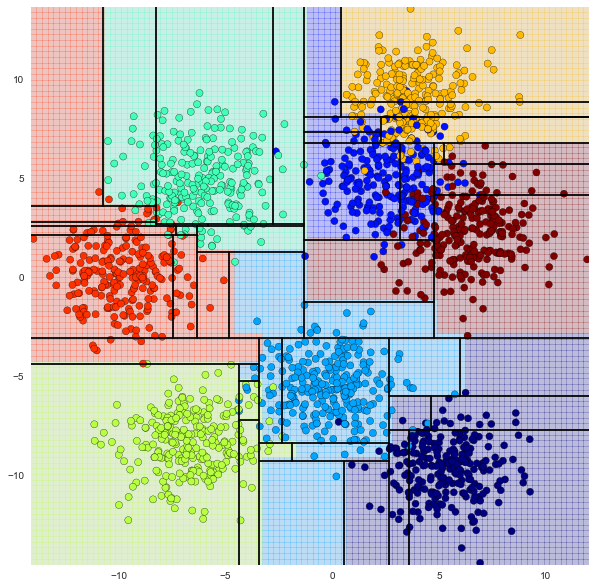
score 0.92500000000000004
けっこういい感じだけど・・・?
決定木の深さを深くすると、正解率は上がる。
しかし過学習になる可能性がある。
過学習(Overfitting)は未知のデータに対して予測が外れやすくなったりするらしいです。
勉強しすぎると頭堅くなっちゃうやつと同じ現象かな
□ランダムフォレスト
[python]
clf = RandomForestClassifier(n_estimators=100, random_state=0)
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
[/python]
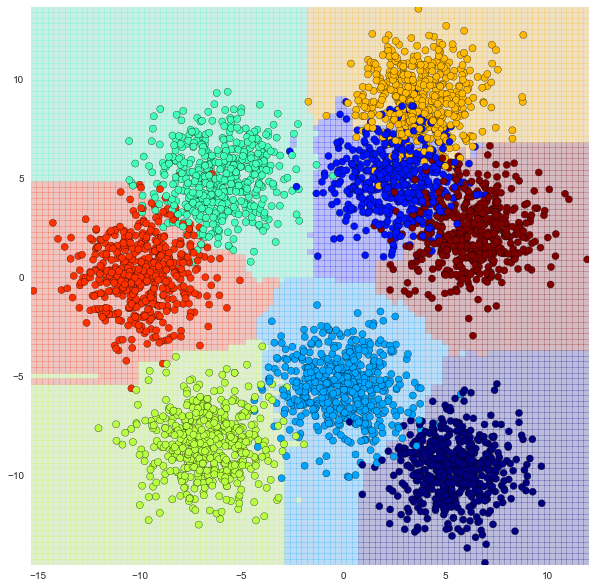
score 1.0
うん?正解率が100%とかあるのかな
まーいいや、とりあいずざっくり決定木とランダムフォレストできました!
