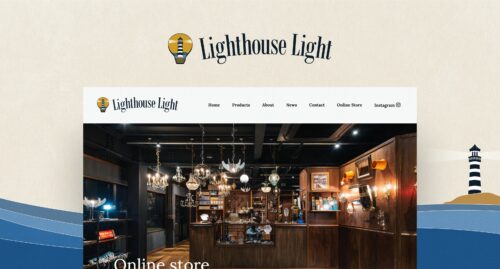
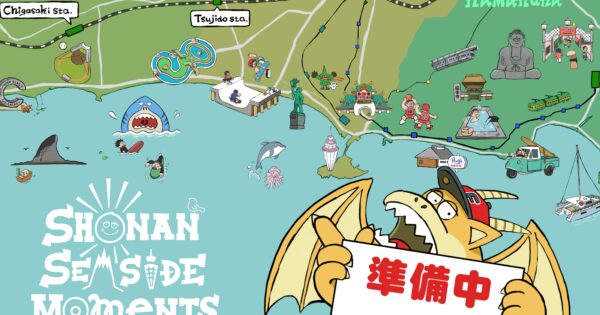
ファンタジーもビジネスも、世界は冒険に満ちています。
この広大なワンダーランドをわくわくしながら生き抜くため
そしてお客様の抱える問題や課題に寄り添うため
私たちはWebへの熱い思いを胸に集った精鋭チームです。
毎日が謎解きの連続。
幾つものダンジョンをクリアしたその先に待つものは
分かち合う喜びと陽光きらめく新しい世界なのです。
この広大なワンダーランドをわくわくしながら生き抜くため
そしてお客様の抱える問題や課題に寄り添うため
私たちはWebへの熱い思いを胸に集った精鋭チームです。
毎日が謎解きの連続。
幾つものダンジョンをクリアしたその先に待つものは
分かち合う喜びと陽光きらめく新しい世界なのです。